
I am a Research Scientist working in DeepMind's vision group. I completed my computer vision Ph.D. in the WILLOW project-team which is part of Inria and Ecole Normale Supérieure, working with Ivan Laptev and Josef Sivic.
My main research interests are video understanding and weakly-supervised machine learning. More generally, I am interested in everything related to Computer Vision, Machine Learning and Natural Language Processing.
During the 2018 summer, I had the chance to collaborate with Du Tran, Heng Wang and Lorenzo Torresani at Facebook AI.
I was also lucky enough to be awarded the Google Ph.D. fellowship in 2018.
Invited talk:

Abstract: We propose to avoid manual annotation and to learn video question answering (VideoQA) from millions of readily-available narrated videos. We propose to automatically generate question-answer pairs from transcribed video narrations leveraging a state-of-the-art text transformer pipeline and obtain a new large-scale VideoQA training dataset. To handle the open vocabulary of diverse answers in this dataset, we propose a training procedure based on a contrastive loss between a video-question multi-modal transformer and an answer embedding. We evaluate our model on the zero-shot VideoQA task and show excellent results, in particular for rare answers. Furthermore, we demonstrate that finetuning our model on target datasets significantly outperforms the state of the art on MSRVTT-QA, MSVD-QA and ActivityNet-QA. Finally, for a detailed evaluation we introduce a new manually annotated VideoQA dataset with reduced language biases and high quality annotations.
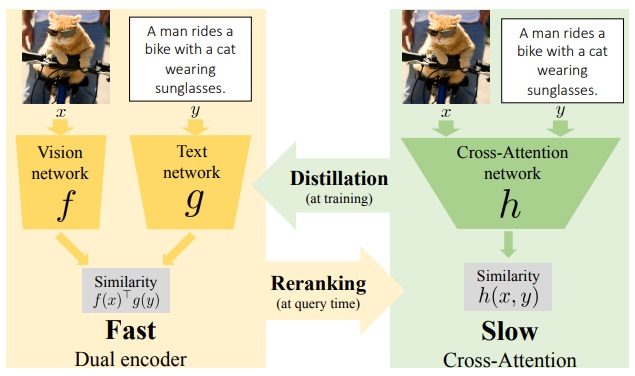
Abstract: Our objective is language-based search of large-scale image and video datasets. For this task, the approach that consists of independently mapping text and vision to a joint embedding space, a.k.a. dual encoders, is attractive as retrieval scales and is efficient for billions of images using approximate nearest neighbour search. An alternative approach of using vision-text transformers with cross-attention gives considerable improvements in accuracy over the joint embeddings, but is often inapplicable in practice for large-scale retrieval given the cost of the cross-attention mechanisms required for each sample at test time. This work combines the best of both worlds. We make the following three contributions. First, we equip transformer-based models with a new fine-grained cross-attention architecture, providing significant improvements in retrieval accuracy whilst preserving scalability. Second, we introduce a generic approach for combining a Fast dual encoder model with our Slow but accurate transformer-based model via distillation and re-ranking.
Abstract: Annotating videos is cumbersome, expensive and not scalable. Yet, many strong video models still rely on manually annotated data. With the recent introduction of the HowTo100M dataset, narrated videos now offer the possibility of learning video representations without manual supervision. In this work we propose a new learning approach, MIL-NCE, capable of addressing misalignments inherent to narrated videos. With this approach we are able to learn strong video representations from scratch, without the need for any manual annotation. We evaluate our representations on a wide range of four downstream tasks over eight datasets: action recognition (HMDB-51, UCF-101, Kinetics-700), text-to-video retrieval (YouCook2, MSR-VTT), action localization (YouTube-8M Segments, CrossTask) and action segmentation (COIN). Our method outperforms all published self-supervised approaches for these tasks as well as several fully supervised baselines.

Abstract: Learning text-video embeddings usually requires a dataset of video clips with manually provided captions. However, such datasets are expensive and time consuming to create and therefore difficult to obtain on a large scale. In this work, we propose instead to learn such embeddings from video data with readily available natural language annotations in the form of automatically transcribed narrations. We introduce HowTo100M: a large-scale dataset of 136 million video clips sourced from 1.22M narrated instructional web videos depicting humans performing and describing over 23k different visual tasks. Our data collection procedure is fast, scalable and does not require any additional manual annotation. Second, we demonstrate that a text-video embedding trained on this data leads to state-of-the-art results for text-to-video retrieval and action localization on instructional video datasets such as YouCook2, CrossTask, MSR-VTT.
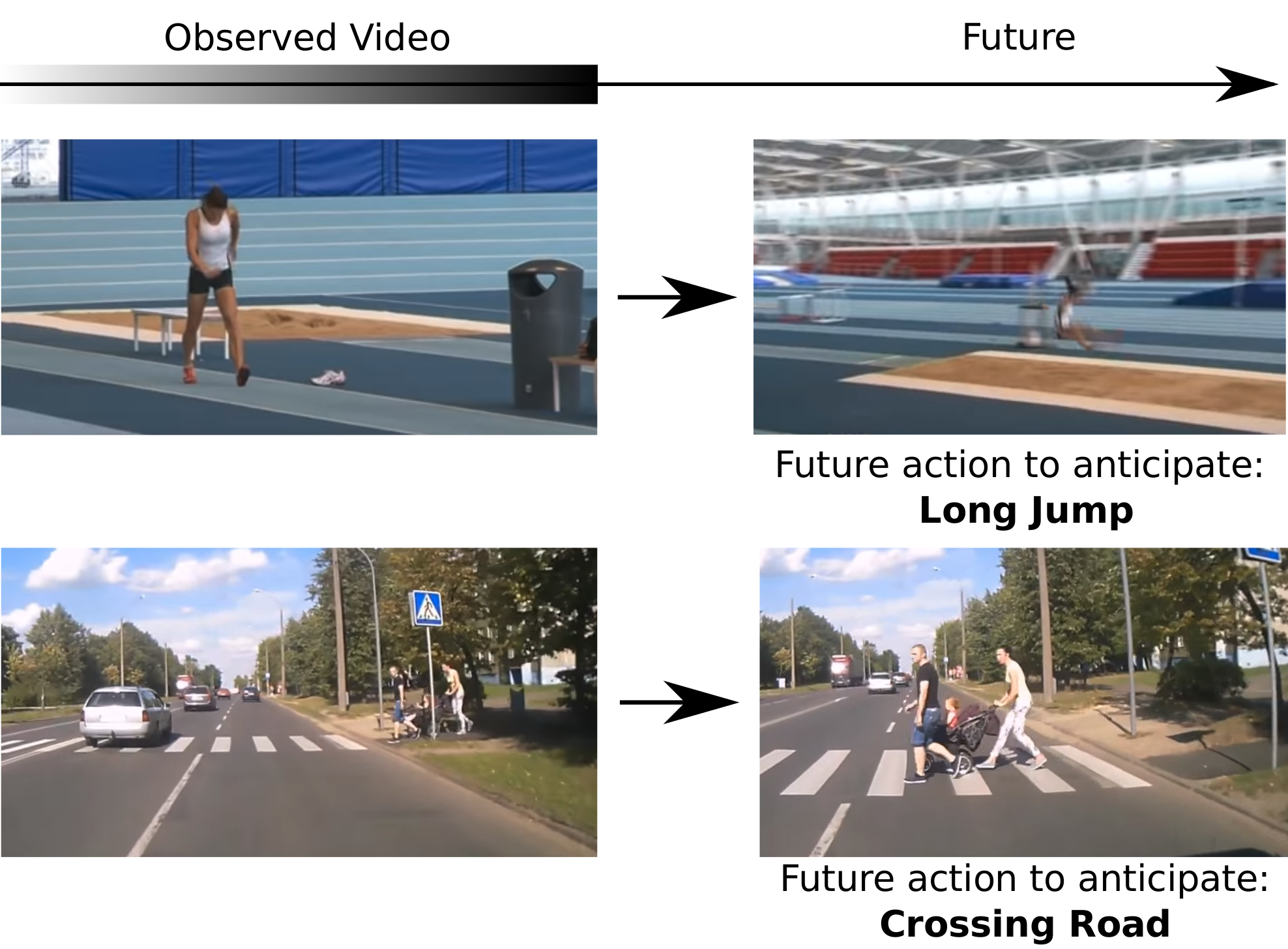
Abstract: Anticipating actions before they are executed is crucial for a wide range of practical applications including autonomous driving and the moderation of live video streaming. While most prior work in this area requires partial observation of executed actions, in the paper we focus on anticipating actions seconds before they start. Our proposed approach is the fusion of a purely anticipatory model with a complementary model constrained to reason about the present. In particular, the latter predicts present action and scene attributes, and reasons about how they evolve over time. By doing so, we aim at modeling action anticipation at a more conceptual level than directly predicting future actions. Our model outperforms previously reported methods on the EPIC-KITCHENS and Breakfast datasets.
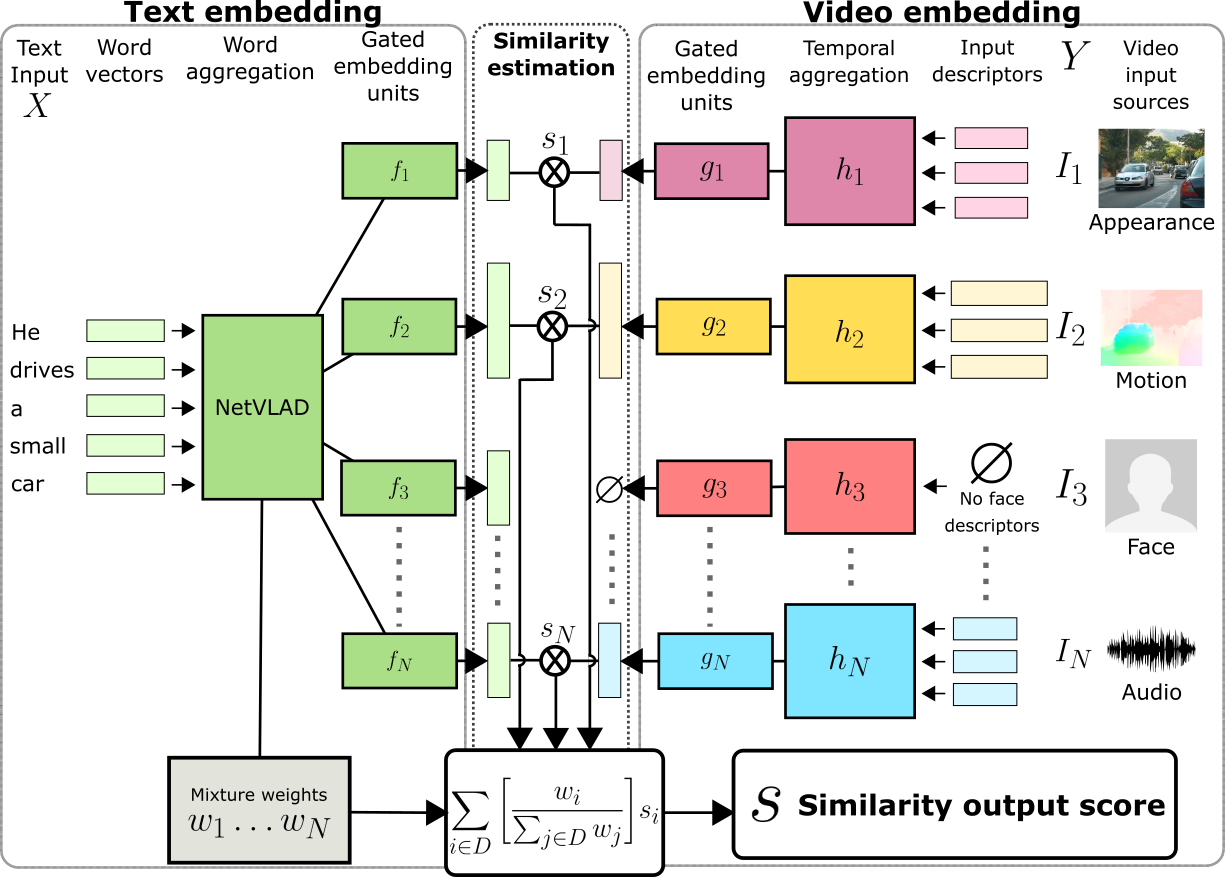
Abstract: Joint understanding of video and language is an active research area with many applications. Prior work in this domain typically relies on learning text-video embeddings. One difficulty with this approach, however, is the lack of large-scale annotated video-caption datasets for training. To address this issue, we aim at learning text-video embeddings from heterogeneous data sources. To this end, we propose a Mixture-of-Embedding-Experts (MEE) model with ability to handle missing input modalities during training. As a result, our framework can learn improved text-video embeddings simultaneously from image and video datasets. We also show the generalization of MEE to other input modalities such as face descriptors.

Abtsract: Discriminative clustering has been successfully applied to a number of weakly-supervised learning tasks. One drawback of discriminative clustering, however, is its limited scalability. We address this issue and propose an online optimization algorithm based on the Block-Coordinate Frank-Wolfe algorithm. We apply it to the problem of weakly-supervised learning of actions and actors from movies and corresponding movie scripts as supervision.

Abtract: We present state-of-the-art end-to-end learnable pooling method for video classification. Our method was used to achieve the best performance in the kaggle Youtube 8M challenge out of 650 teams.

MEE Text-to-Video Search Engine is Text-to-Video web demo search engine based on our proposed Mixture-of-Embedding-Experts (MEE) model. The model was trained on the MPII movie training set and it is tested on both MPII validation and test set and the MSR-VTT dataset. Our web demo runs in real time on a CPU based machine.

Video Dataset Overview is a Searchable and sortable compilation of annotated video datasets I am currently maintaining. It is supposed to help people to have a global overview of the existing annotated video datasets as well as some important features such as their size, published year or annotation type.

LOUPE (Learnable mOdUle for Pooling fEatures) is a Tensorflow toolbox that implements several modules for pooling features such as NetVLAD, NetRVLAD, NetFV and Soft-DBoW. It also allows to use their Gated version. This toolbox was mainly use in the winning approach of the Youtube 8M Large Scale Video Understanding challenge.

The Data Science Game is a student only and worldwide machine learning competition. I have been involved in the project in 2016 and 2017 as an organizer.
The 2016 edition was very successful, we got invited at NIPS 2016 CiML Workshop to present this poster.